| Свежий номер №30 (455) / Классификация текстов Дата публикации: 02.08.2002 Андрей Чеповский, bfchep@supercompilers.com Канва Сегодня в России и в мире действует целый ряд систем классификации больших объемов текстовой информации, в основе которых лежат технологии компьютерной лингвистики и алгоритмов распознавания образов. Принципы построения таких систем довольно универсальны. Набросаем сначала общую схему. Задача состоит в определении принадлежности входного текста одному или нескольким классам (или подклассам). Принадлежность к тому или иному классу может определяться общей тематикой текстов, упоминанием определенных имен, другими условиями, иногда довольно сложными - все зависит от того, как обучить систему. В упрощенном виде подготовка системы к работе выглядит (для внешнего пользователя) примерно так. Пользователь определяет, какого типа тексты следует обработать и в какие «корзинки» (классы) разложить. Затем эксперты отбирают (как правило, несколько десятков) типичных, по их мнению, текстов для каждого класса. Это - набор обучающих текстов, он «загружается» в систему классификации в режиме обучения После того, как обучение закончено, система способна распределять по классам огромные потоки текстовой информации. В России существуют системы классификации, обрабатывающие мегабайты текста (в среднем несколько тысяч документов и информационных сообщений) в секунду. В частности, такая система создана в Исследовательском центре искусственного интеллекта Института программных систем РАН (ИЦИИ ИПС РАН). Высокая скорость достигается при реализации систем классификации на кластерных вычислителях; заметим, что эти задачи тривиальным образом распараллеливаются: одна и та же программа независимо обрабатывает потоки данных в каждом узле кластера. Теперь расскажем чуть подробнее об алгоритмах, применяющихся в таких системах.
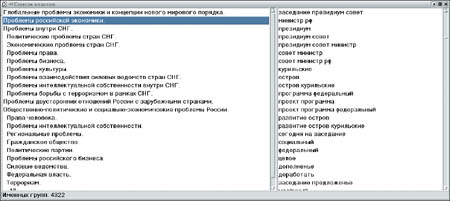
Кухня Задачу классификации текстов можно интерпретировать по-разному. С математической точки зрения - это задача распознавания образов в алгебраической постановке, а значит, для ее решения можно использовать те же принципы, что и для моделирования поведения живых организмов, прогнозирования запасов месторождений полезных ископаемых, оценки технологических процессов, распознавания графических объектов и пр. При таком подходе для каждого объекта выделяются наборы признаков. В случае текстов признаками являются слова и взаимосвязанные наборы слов, содержащиеся в текстах. Информация о признаках сводится в таблицу, которая называется информационной матрицей. Каждая строка матрицы соответствует одному из классов, каждый элемент строки - одному из признаков; численное значение этого элемента определяет, условно говоря, «вес» признака при принятии решения о принадлежности к данному классу. «Веса» вычисляются в процессе обучения при помощи статистических алгоритмов. Когда обучение завершено, принадлежность незнакомого текста к одному из классов устанавливается также путем статистического анализа обнаруженных в тексте признаков (с учетом их «весов»). Описанная схема довольно проста, а существующие алгоритмы позволяют проводить классификацию с очень высокой достоверностью. Но такой результат достигается за счет огромных размеров информационной матрицы, длина строки которой исчисляется многими тысячами элементов (общим числом характерных слов и словосочетаний). Для построения же самого набора признаков используются методы структурной лингвистики. Примеры признаков и классов можно увидеть на рисунке. Как обучающие, так и классифицируемые тексты сначала обрабатываются программами предварительного парсирования (parsing) - для разделения на предложения и слова. Далее в работу вступают модули морфологии и частичного синтаксического анализа. Первый из них ищет для каждого слова так называемую нормальную форму и определяет, в какой форме (падеже, склонении) оно используется в данном предложении. Второй модуль устанавливает связанность различных слов в предложении. Все лингвистические модули, работающие в подобных системах, по-своему уникальны и несопоставимы по качеству с теми, что используются в массовых продуктах. Вот пример, иллюстрирующий специфичность решаемых ими лингвистических задач: применяемые в этих системах словари для морфологического разбора содержат все встречающиеся на территории России топонимы, около ста тысяч фамилий, имен и отчеств, а также все их формы. Разумеется, такие словари во много раз превышают по объему аналогичные словари, использующиеся в коммерческих системах автоматического перевода. Тем не менее, модули морфологического разбора в ряде систем классификации работают быстрее большинства своих коммерческих аналогов, поскольку они построены на несколько иных алгоритмах 1. Последнее замечание относится и к модулям частичного синтаксического анализа, задача которых - найти все связанные многословные группы в каждом предложении текста (для последующего сравнения с признаками классов). Эта задача заведомо проще, чем полный синтаксический анализ предложения. Однако проблема в том, что модуль должен решать ее практически без ошибок - иначе он будет непригоден для систем классификации. При этом прямой перебор вариантов связей для каждого слова, полученных на выходе модуля морфологии, неприемлем из-за слишком большого времени работы программы. Замечу напоследок, что такие системы классификации - не «коробочные продукты» и на массового пользователя не рассчитаны. Позволю себе дать прогноз, который может возмутить некоторых специалистов: в ближайшее время будет продемонстрировано, что системы классификации, построенные по таким принципам, смогут решать задачи определения эмоционально-психологической направленности текстов и выделения системных установок, заложенных в тексте.
1 (обратно к тексту) - Кстати, неожиданным может показаться такое утверждение: для получения высоких результатов в этой области приходится отказаться от многих достижений модного сегодня объектно-ориентированного подхода.
|