ПИ-СИАЙ-экспресс
Автор: Сергей Озеров
Опубликовано в журнале "Компьютерра" №23 О шине PCI Express (в девичестве 3GIO) мы уже писали неоднократно. Разговор о ней заходил на любой IT-выставке или конференции - например, на ежегодных Intel Developer Forum (IDF).1. Собственно, именно корпорация Intel является сейчас одним из апологетов продвижения этой шины на рынок, хотя исходно архитектура будущей PCI Express была предложена несколько лет назад рабочей группой Arapahoe, основанной компаниями Compaq, Dell, IBM, Intel и Microsoft при участии организации PCI-SIG. Необходимость обзора PCI Express назрела уже давно, поскольку скоро ожидается выход материнских плат и карт расширения, поддерживающих эту технологию. Поэтому поговорим об устройстве, назначении, достоинствах, недостатках и грядущих перспективах "третьего поколения шин ввода-вывода"2Конец эпохи параллельных шин данных По прогнозам, за следующие десять лет требования к пропускной способности шин ввода-вывода возрастут в 50 раз. Но традиционная архитектура параллельных шин типа PCI и AGP уже почти достигла предела своих возможностей (физический лимит для них - примерно 1 ГГц). PCI Express призвана заменить шину PCI (и ее клон - AGP), исправно работающую в компьютерной технике уже более десяти лет3. Напомним, что PCI в свое время пришла на смену "первому поколению" - шине ISA4. Однако на сей раз изменения при переходе на новый стандарт куда большие, чем при переходе от ISA к PCI, - они в PCI Express носят не столько количественный, сколько качественный характер, и в целом их можно охарактеризовать как "переход от параллельных шин к последовательным", что является сейчас общеиндустриальной тенденцией развития шин передачи данных (см., например, рис. 1 и www.terralab.ru/system/20465). 5
В то время как процессоры уже не первый год успешно движутся в направлении параллельных архитектур (SIMD-расширения, суперскалярность, конвейеризация, Hyper-Treading и многоядерность), шины передачи данных не менее успешно переходят на последовательные решения. Причины обеих тенденций схожи и довольно просты - необходимо сбалансированно наращивать производительность всех компонентов компьютеров, однако не всякие существующие архитектурные решения способны эффективно масштабироваться. Микропроцессорам проще работать с параллельными шинами передачи данных, они обеспечивают лучшую производительность при меньшей частоте, но, к сожалению, их тяжело масштабировать на высокие частоты - при этом сильно повышаются требования к физической разводке шины, заметно возрастает латентность (чтобы синхронизировать "одновременные" сигналы во всех проводах шины), да и места они занимают много - сравните, например, шлейфы IDE (UltraATA) и SerialATA. Поскольку себестоимость производства чипа сегодня все равно выходит примерно одинаковой (если не считать экономию на "ножках микросхемы"), то порой дешевле делать более сложный кристалл контроллера шины, чем плодить золотые контакты и многочисленные проводники на печатной плате. Поэтому стремление разработчиков перейти на параллельные шины довольно естественно - хотя бы с точки зрения экономии контактов и места на разводку шины (см. врезку вверху).6 С другой - последовательную шину гораздо проще заставить работать на повышенных тактовых частотах7, поэтому удается значительно поднять производительность. Более того, отличная масштабируемость последовательных шин вроде PCI Express и HyperTransport относительно легко достигается путем как повышения частоты работы, так и добавлением нескольких последовательных линий к шине. PCI Express разработана с расчетом на разнообразные применения - от полной замены шин PCI и PCI-X в настольных компьютерах и серверах до использования в мобильных, встроенных и коммуникационных устройствах. Номинальной рабочей частотой шины PCI Express является (держитесь!) 2,5 ГГц. При этом пиковая производительность (на один канал передачи данных, без учета двунаправленности) всего на 50% больше, нежели производительность "обычной" 33-мегагерцовой PCI - 200 против 133 Мбайт/с. То есть для перехода на последовательную шину с сопоставимой производительностью понадобилось 75-кратное (!) увеличение тактовой частоты - до значений, о которых два-три года назад можно было только мечтать. еудивительно, что PCI Express появилась только сегодня - раньше для нее просто не было технических предпосылок.
Локальная сеть в пределах компьютера Итак, что же нам предлагается? Разработчики PCI Express не стали изобретать велосипед и взяли за основу наработки в области сетевого оборудования. Получилось что-то очень напоминающее Gigabit Ethernet - и на физическом уровне, и на уровне протоколов передачи данных. Первое и самое главное отличие новой шины: PCI Express является последовательной, а значит, четко разнесены уровни представления данных и уровень их передачи. Если в параллельной шине, например PCI, данные непосредственно появляются на шине (вместе с какой-то дополнительной информацией - CRC, адресом получателя и пр.), что и обуславливает простоту их посылки и получения, то в последовательной шине сказать что-либо о "физическом носителе" заранее невозможно. Информация, которую необходимо передать, просто упаковывается в пакеты, куда заносятся данные о получателе и коды обнаружения/исправления ошибок - а получившийся сплошной поток (где идут вперемешку данные, приложения и вспомогательная информация) уже передается - абсолютно неважно каким способом - через физическую среду. Приемник, в свою очередь, распаковывает прибывшие пакеты, исправляет ошибки или запрашивает повторную передачу, определяет получателя и направляет пакет далее. Собственно, "последовательность" шины вовсе не значит, что данные передаются побитно (хотя в случае с PCI Express это так), а понимается в том смысле, что данные и служебная информация передаются последовательно, по одним и тем же каналам (в отличие от параллельной передачи той же информации). Стандарт PCI Express предусматривает схему организации данных, показанную на рис. 2.
Не вдаваясь в технические подробности (их можно найти, например, на www.terralab.ru/system/34069), скажу лишь, что PCI Express использует традиционную многоуровневую модель, аналогичную сетевой ISO/SOI. На самом верхнем уровне располагаются прикладные приложения, использующие PCI-устройство. Для них в новой схеме не меняется ровным счетом ничего - для передачи или приема данных через шину PCI приложения обращаются к операционной системе, причем все старые операционки как работали с PCI, так и будут работать с PCI Express. Хотя для полноценной реализации всех возможностей новой шины (скажем, горячего подключения устройств), не предусмотренных в предыдущем стандарте, потребуется немного модифицировать ОС. В случае продукции Microsoft полноценная поддержка PCI Express обещана, увы, лишь в Longhorn, но возможны соответствующие "заплатки" и к некоторым существующим системам. Те же слова справедливы и для драйверов оконечных устройств. Однако все последующие уровни уже относятся к "железной" реализации, и здесь происходят кардинальные изменения. Прежде всего, добавлено два новых уровня (Transaction Layer и Link Layer), которые иначе, как TCP и IP не назовешь - выполняемые функции абсолютно те же, что и у "сетевых" аналогов. Transaction Layer заведует первоначальной упаковкой данных, передачей их конкретному получателю и гарантиями корректной доставки сообщения. Link Layer указывает физический адрес назначения пакета, по которому контроллеры шины принимают решение о направлении пакета в конкретную физическую линию, здесь же располагается код обнаружения и исправления ошибок в принятом пакете (CRC), номер пакета, позволяющий отличить один пакет от другого, и др. Однако, в отличие от TCP/IP, маршрутизация пакетов (принятие решений о том, на какую шину перенаправить пакет, какой из нескольких претендующих пакетов передать первым) осуществляется на уровне транзакций. Интересно также, что пакет передается только в том случае, когда поступил сигнал готовности от буфера приема. Как следствие, уменьшается число повторов пакета и шина используется более эффективно. Формат пакетов шины PCI Express показан на рис. 3.
В низу этой пирамиды размещается собственно физическая реализация шины передачи данных - это две дифференциальные пары проводников с импедансом 50 Ом (первая пара работает на прием, вторая - на передачу), данные по которым передаются с использованием избыточного кодирования по схеме "8/10" с исправлением ошибок.8 Это позволяет исправлять многие простые ошибки, неизбежные на столь высоких частотах, без привлечения протоколов вышележащих уровней и без лишних повторных передач. Кроме того, это нужно, чтобы уменьшить долю "постоянных" составляющих в сигнале (не более четырех нулей или единиц подряд, рис. 4) - обеспечить баланс дифференциальной пары по постоянному току и позволить приемнику уверенно синхронизироваться по фронтам поступающего сигнала, поскольку никакого дополнительного ("внешнего") синхронизирующего сигнала от тактового генератора в PCI Express не используется.9 В качестве рабочих напряжений выбраны уровни от 0,2 до 0,4 В для логического нуля и от 0,4 до 0,8 В для логической единицы.10
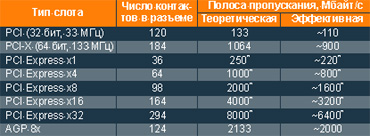
Как и в любой сети, передаваемые данные дополнительно нарезаются небольшими кусочками - фреймами. При тактовой частоте шины 2,5 ГГц мы получим скорость 2,5 Гбит/с. С учетом выбранной схемы "8/10" выходит 250 Мбайт/с, однако многоуровневая сетевая иерархия не может не сказаться на скорости работы, и реальная производительность шины оказывается значительно ниже - всего лишь около 200 Мбайт/с в каждую сторону. Впрочем, даже это на 50% больше, чем теоретическая пропускная способность шины PCI. Но это далеко не предел: PCI Express позволяет объединять в шину нескольких независимых линий передачи данных. Стандартом предусмотрено использование 1, 2, 4, 8, 16 и 32 линий - передаваемые данные поровну распределяются между ними по схеме "первый байт на первую линию, второй - на вторую, ..., n-й байт на n-ю линию, n+1-й снова на первую, n+2 снова на вторую" и так далее. Это не параллельная передача данных и даже не увеличение разрядности шины (поскольку все передающиеся по линиям данные передаются абсолютно независимо и асинхронно) - это именно объединение нескольких независимых линий. Причем передача по нескольким линиям никак не влияет на работу остальных слоев "пирамиды" и реализуется сугубо на "нижнем", физическом уровне. Именно этим достигается прекрасная масштабируемость PCI Express, позволяющая организовывать шины с максимальной пропускной способностью до 32x200=6,4 Гбайт/с в одном направлении (см. табл. 1), под стать лучшим параллельным шинам сегодняшнего дня.11
PCI Express относится к шинам класса "точка-точка", то есть одна шина может соединять только два устройства (в отличие от PCI, где на общую шину "вешались" все PCI-слоты компьютера), поэтому для организации подключения более чем одного устройства в топологию организуемой PCI Express, как и в Ethernet-решениях на базе витой пары или устройствах USB, придется вставлять хабы и свитчи, распределяющие сигнал по нескольким шинам. Это тоже одно из главных отличий PCI Express от прежних параллельных шин. Впрочем, на схеме (рис. 2) физический уровень не зря "троится" - на самом деле, в качестве "физического носителя" PCI Express может выступать что угодно, хоть тот же Gigabit Ethernet! Во-первых, это позволит по мере развития электроники легко нарастить тактовую частоту шины (ее обещают поднять вчетверо и довести до 10 ГГц, что уже вплотную приближается к теоретическому пределу передачи сигнала по медным соединениям, оцениваемому в 15–20 ГГц, см. www.terralab.ru/system/20465) без малейшего ущерба для совместимости с приложениями и драйверами. А во-вторых, это позволит реализовывать необычные по меркам сегодняшнего дня решения. Как вам нравится идея разделить системный блок на две части? Северный мост, процессор, память, видеокарта и, возможно, HDD c прочими "системными" компонентами останутся в одной половине, которую можно будет задвинуть куда-нибудь подальше и никогда ее не трогать. А южный мост и всю периферию - оптические приводы, дисководы и картоводы, звуковую карту, USB 2.0, FireWire и все соответствующие выходы - можно поместить в компактный и красивый корпус, который, скажем, может служить подставкой для монитора. Налицо все преимущества баребонов, и никаких проблем с апгрейдом и перегревом компонентов (можно будет, наконец, реализовать заветную мечту оверклокеров: поместить системный блок в холодильник, но так, чтобы работа с ним не затруднялась). Соединяться "половинки" компьютера будут как раз по единственной шине PCI Express, хотя физический носитель в этом случае, конечно, будет совсем другой - например, оптический. Фантастика! Появились в стандарте PCI Express (по сравнению с PCI) и другие новые возможности, - например, поддержка виртуальных каналов, QoS (Quality of Service) и изохронная передача данных. Подробнее об этом читайте в расширенной версии обзора на www.terralab.ru/system/34069. Аппаратные конфигурации В плане практической реализации шина PCI Express представляет собой целый аппаратный комплекс, затрагивающий северный и южный мосты чипсета, коммутатор и оконечные устройства. Новым термином здесь является коммутатор (switch), заменяющий одну шину со многими подключениями коммутируемой технологией (рис. 5).
Коммутатор обеспечивает одноранговую связь между различными оконечными устройствами, то есть снижает нагрузку на мост. Поддерживаются несколько виртуальных каналов на один физический. Примерные схемы внедрения PCI Express в настольный компьютер и сервер представлены на рис. 5.
В "десктопных" системах PCI Express 16x в первую очередь вытеснит AGP 8x в качестве "графической шины", соединяющей видеокарту и северный мост чипсета. Затем на PCI Express пересадят многие интегрированные устройства - гигабитный сетевой и RAID-контроллеры. К обычным PCI-слотам добавят PCI Express x1. В качестве межчипсетной шины (соединяющей мосты чипсета) PCI Express будет выступать вместе со старыми шинами (VIA VLink, SiS MuTIOL) - некоторые производители чипсетов пока не желают отказываться от своих проприетарных шин.
С серверными архитектурами все проще - там не предусматривается традиционной "двухмостовой" чипсетной схемы. На PCI Express переведут интегрированные гигабитные сетевые контроллеры; традиционные периферийные шины (PCI-X, SATA, LPC) сохранятся, но к чипсету будут подключаться через специальные мосты на шину PCI Express. Аналогичная схема предусмотрена для сетевых решений - однако в силу специфики периферии там новая шина вытеснит почти все остальные. Как видно из рисунков, PCI Express предполагается использовать для связи всех ключевых компонентов системы, кроме "внешних" (USB 2.0) и накопителей на магнитных дисках (SATA как более подходящий для работы именно с HDD). Некоторое время слоты PCI и PCI-X продолжат существование (они будут организованы через специальные мосты), но почти все интегрированные контроллеры будут подключаться уже с использованием PCI Express. В том числе PCI Express свяжет между собой северный и южный мосты чипсета. Поскольку реализация что AGP, что PCI Express x16 требует весьма сложной разводки, то слот AGP из будущих чипсетов исчезнет12 (впрочем, SiS, VIA и ALi на первых порах будут выпускать чипсеты с шиной AGP и PCI Express x1, но без PCI Express x16 - см., например, фото слева). Краткие итоги Как бы мы ни относились к новой шине, постепенный переход на PCI Express неизбежен. Технология очень интересная, с огромным потенциалом и отличными возможностями - прекрасный преемник "старичка" Peripheral Component Interconnect на ближайшие 8-10 лет. Возможно, чуть преждевременная для "обычных пользователей", но в будущем необходимая. Если же рассматривать конкурентов - шины PCI-X, HyperTransport (о ней - в следующей статье) или RapidIO, то война не состоится - уж слишком все эти шины разные и нацелены каждая на свой "кусок пирога" (сегмент рынка), хотя у PCI Express этот "кусок", безусловно, самый смачный, а применение остальных шин достаточно специфично. AMD уже поддержала стандарт PCI Express (продолжая развитие своего HT, разумеется). Так и напрашивается аналогия с противостоянием замечательного интерфейса FireWire (IEEE 1394/b) и USB 2.0. Первый всем был хорош, да только так и остался узкоспециализированным решением, задавленным бесплатным "ставленником" Intel. Что касается применения PCI Express в качестве шины памяти или процессора (системной), то это совершенно отпадает, поскольку ее текущие возможности (максимум 6,4 Гбайт/с) явно не способны удовлетворить будущим запросам этих шин. В этом смысле шинам AMD HyperTransport и Rambus Redwood/XDR (о них читайте ниже) нечего бояться. 1 Cм. обзоры www.terralab.ru/system/170309 , .../20465, .../23898, .../24500, .../29301, .../29386 и .../32360/page2.html.
|