Свежий номер №41 (370) / Клевый чтец Евгений Козловский, ekozl@computerra.ru 22.11.2000 В незапамятном 1994 году я выпустил книжку «Как нам купить и обустроить компьютер», в которой впервые представил FineReader (тогда еще от BIT) и назвал его Клёвым Чтецом (КЧ). Оно, может, для торговой марки, претендующей (и как показали последние годы - с успехом) на всемирное распространение, слишком игриво, но, согласитесь, больше по-русски. Я уж и не помню, какую версию FineReader’а я имел в виду, третью, а скорее даже вторую: факт тот, что Клёвый Чтец еще тогда читал более чем клёво, иначе я ничего про него не сказал бы или обругал. Самая первая версия, помню, работала кое-как, но это почему-то не отвратило меня от программы, и в результате я был вознагражден. Уже несколько лет я не представляю свою компьютерную жизнь без КЧ, как минимум - я распознаю с его помощью обложки компакт-дисков (для поддержания в актуальном состоянии каталога), которых у меня все прибавляется и издатели которых все более изощряются в отношении шрифтов, расцвечиваний, подкладываний картинок и прочих красот. Дисков у меня под тысячу, и честно признаюсь, что без КЧ никакого каталога бы просто не было. Когда речь идет о распознавании типографского или принтерного текста, КЧ еще с третьей версии делает ошибок так мало, что ими можно пренебречь. Я помню, как КЧ-3, которому я скормил 530 страниц текста моего романа «Мы встретились в Раю…», отпечатанного в питерском «Печатном дворе» офсетным способом, сделал, дай бог, десяток ошибок!!! Зачем же в таком случае, - можете поинтересоваться вы, - понадобились версии четвертая, пятая… Блестящий практический ответ на это дал Сергей Голубицкий в «Голубятне» «Acid test» («КТ» #360): для всё более уверенного распознавания всё менее качественных текстов, например - пятой машинописной копии, сделанной двадцать лет назад и успевшей выцвести так, что и глазами-то не прочтешь. Ну и, конечно, для всяких бантиков и примочек, которые не есть суть (ибо количество таланта, креативности, потребных для их сочинения и реализации, даже примерно нельзя сравнить с количеством тех же свойств, потребных для создания главного алгоритма, алгоритма собственно распознавания), но несут Итак, от версии к версии FineReader’а повышается процент уверенно распознаваемого текста, - и если ваши задачи в этом смысле просты, вы, наверное, и в самом деле разницу можете не почувствовать; если же сложны - у вас не остается другого выхода, как попробовать эту, следующую, пятую, версию: скорее всего, задачи станут решаться легче. О распознавании мы на этом закончим: по моему опыту (правда, я не проводил специальных исследований), программы, распознающей лучше FineReader’а, не существует. Уж во всяком случае - для русского языка: прочую сотню языков, которую поддерживает Клёвый Чтец, я и пользую реже, и понимаю хуже, - но слышал, что и с этой сотней дело обстоит примерно так же, как с русским. Ну, а что у КЧ получается пока не идеально (самые сложные задачи), так это просто состояние дел с искусственным интеллектом на сегодня. Пожалуй, единственный недостаток, который я - в смысле распознавания - отмечаю у всех известных мне версий FineReader’а, - это неумение уверенно выделить текстовую информацию, когда текст набран цветным, иной раз - с ползучим цветом, - на цветном же графическом фоне (рис. 1). Когда мне попадается такого стиля обложка компакта, я сканирую ее в Photoshop’е, там играю с заменой цветов, их яркостью и насыщенностью, пока не свожу картинку к серой с удовлетворительно читающимся текстом, - и уже этот файл предлагаю FineReader’у, после чего все идет как по маслу. Не могу сказать, насколько сложно формализовать и записать в виде алгоритма мои действия в Photoshop’е: возможно, это задача посложнее самого распознавания; а может, такие потребности, как у меня, встречаются нечасто, и просто коммерчески невыгодно тратить слишком много усилий на улучшения, неспособные принести адекватную прибыль, - просто констатирую. Впрочем, можно считать, что первый шаг в этом направлении FineReader уже сделал: пятая версия позволяет (по вашему требованию) сканировать текст не только в черно-белом варианте или в серой шкале, но и в цвете, - и тогда при распознавании красный текст будет отображен красным цветом, синий - синим и так далее. Теперь о примочках. Конечно, не обо всех: никакого места не хватит в журнале, - а об особо порадовавших практически или хотя бы (в некоем идеальном смысле) восхитивших интеллектом и изобретательностью создателей. О неимоверной уйме поддерживаемых языков (их число растет от версии к версии) я уже написал, здесь - конкретизирую: в стандартной, базовой версии насчитывается 121 язык, в расширенной Cyrillic Plus - целых 176: к латинице и греческому добавляется кириллица. Кроме общеупотребительных мировых языков, в пятой версии есть, например, абхазский, татарский, алтайский, киргизский, конго, корсиканский, корякский, коса (один из языков банту. Распространен в ЮАР. Носителей около 8 млн. человек), кпелле, кроу и тому подобные. Кроме того, добавлено распознавание языков искусственных: идо (реформированный эсперанто), интерлингва, окциденталь и эсперанто, - и языков программирования: Basic, С/С++, Cobol, Fortran, Java и Pascal. Распознает пятый FineReader и простые химические формулы. Это, безусловно, расширит круг покупателей, хотя вообразить, что кому-нибудь понадобится ввести в компьютер пыльный листинг программы на Бейсике, провалявшийся за шкафом добрый десяток лет… Ну, разве для полного собрания сочинений. Так или иначе, лиха беда - написать алгоритм распознания одного языка, их добавление уже дело техники. Будем ждать шестой версии, когда уж ничего не останется программистам из ABBYY, как добавить языки арабские и иероглифические дальневосточные. Тогда-то мы и покорим уже весь мир :-). Далее: теперь FineReader, получив отсканированную картинку, сам разбивает ее на блоки по смыслу. То есть такой режим можно было задать и раньше, но раньше блоки получались подряд, а тексты порою бывают сверстаны очень даже неординарно, - теперешний КЧ сперва в тексте разбирается, пытается (и часто - небезуспешно) понять, что должно идти за чем, и только потом уж делает окончательную разбивку. Удобно? В некоторых ситуациях - более чем. Однако при сканировании очередной обложки компакт-диска мне пришлось вручную заставлять FineReader 5.0 не разбивать текст на две колонки, в одной из которых был список треков, во второй - их длительность, - то есть, в сущности, колонка была одна И к прежним FineReader’ам был подключен простенький модуль проверки орфографии от фирмы BIT (девичья фамилия ABBYY), - неузнанные слова выделялись цветом и пр. Теперь эта группа возможностей доведена до предела/совершенства: мощный спеллчекер с возможностью добавления в словарь словоформ, сделанный в de facto-стандарте Word’а, поможет вам вычистить те немногие ошибки, которые, возможно, произошли при распознавании. И, прежде чем перейти к рассказу о примочке, более всего меня порадовавшей в новом FineReader’е, - парочку примыкающих к ней возможностей. Раньше распознанный текст можно было передать в Word или, скажем, в переводчик Stylus (PROMT). Теперь, не только оставив эту возможность в неприкосновенности, но и сильно расширив список принимающих программ, FineReader можно, нажав на кнопочку, появляющуюся на верстаке, вызвать прямо из Word’а (рис. 2): картинка сканируется, разбивается на блоки, распознается (причем графические элементы грамотно детектируются и в таком виде и переносятся), - и вы имеете прямо в Word’е малоотличимую (а порой и неотличимую - все зависит от оригинала и набора установленных в системе шрифтов) копию. В которой, скажем, делаете несколько нужных поправок и отправляете на принтер. Или в Web, - но тут Word уже и не нужен: при переводе оригинала в Web-формат FineReader, на мой взгляд, делает просто чудеса идентичности. И вот она, та самая примочка: вы можете положить на планшет сканера документ, отсканировать, распознать, а потом сохранить в PDF-формате с текстом поверху или под картинкой. То есть у вас получается графическая копия, которую довольно легко вытащить из недр винчестера с помощью обычного текстового поиска. Например, вы выкладываете весь сканерный планшет визитными карточками, запоминаете, отсканировав и распознав, в PDF-формате со скрытым текстом под картинкой, далее - набираете в поиске нужную вам фамилию - и получаете графический образ визитки ее владельца. Тот же упомянутый выше каталог компакт-дисков, пожалуй, куда лучше смотрелся бы в виде снимков дисковых обложек, - коль есть возможность для автоматического текстового поиска нужного диска. Ибо еще одна из насущных задач искусственного интеллекта - поиск в графических базах данных - очень и очень далека от решения даже в первом практическом приближении. Увы, бочонок PDF-меда я вынужден разбавить добрым черпаком дегтя: поиск в PDF-файлах русских слов не поддерживается. ABBYY, правда, здесь не при чем, претензии - к Adobe, но не знаю, как вам, а мне от этого не легче. Правда, господа из ABBYY надеются уломать Adobe «уинтернационалить» формат, но при том соотношении купленных/украденных Adobe-продуктов, которое имеет место быть в непонятой умом России, я слегка сомневаюсь в успехе предприятия. Еще одна прикольная примочка есть только в полном варианте пятого FineReader’а, называемого по моде последнего времени - Office. Это - сканирование разного рода анкет (например, для получения визы в американском посольстве), при котором текстовые поля можно заполнять на компьютере, а при распечатке анкета не теряет своей оригинальной композиции. Места на то, чтобы описать все новости пятой версии, в журнале все равно не хватит, поэтому волевым образом останавливаюсь прямо здесь, будучи уверен, что вы сами скоро исследуете нового Клёвого Чтеца, - тем более что он уже появился в продаже (своими глазами видел на Горбушке недорогую пиратскую копию). О последнем факте я упомянул с двумя целями: во-первых, когда Сергей Леонов в «Каналах» написал, что пятый FineReader уже лежит на Горбушке, он получил отповедь от ABBYY, - отповедь вроде бы справедливую, однако и не совсем. Я, конечно, понимаю, что вряд ли возможно убедить фирму, живущую с написания софта, что в пиратстве нет ничего ни плохого, ни хорошего, что это реальное отражение процессов, происходящих «в области копирайта». А во-вторых, я полагаю, что на Горбушку попадают продукты исключительно клёвые, в связи с чем предлагаю считать появление пиратского КЧ за его народное признание. [i37038]
|
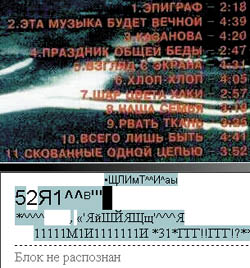 удобства и удовольствия, комфорт: на УАЗике ездить можно вполне, даже порой вездеходнее, чем на каком-нибудь «Чероки», - однако на «Чероки» - куда приятнее.
удобства и удовольствия, комфорт: на УАЗике ездить можно вполне, даже порой вездеходнее, чем на каком-нибудь «Чероки», - однако на «Чероки» - куда приятнее.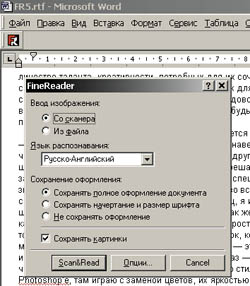 - только эдак раздельно сверстанная. Однако, слава богу, программа оставляет возможность такого ручного командования за пользователем.
- только эдак раздельно сверстанная. Однако, слава богу, программа оставляет возможность такого ручного командования за пользователем. Евгений Козловский
Евгений Козловский